A study by an international team of researchers estimated the proportion of healthcare interventions tested within Cochrane Reviews that are effective according to high-quality evidence.
They selected a random sample of 2428 (35%) of all Cochrane Reviews published between 1 January 2008 and 5 March 2021 and extracted data about interventions within these reviews that were compared with placebo, or no treatment, and whose outcome quality was rated using Grading of Recommendations Assessment, Development and Evaluation (GRADE). They then calculated the proportion of interventions whose effectiveness was based on high-quality evidence according to GRADE, had statistically significant positive effects and were judged as beneficial by the review authors. They also calculated the proportion of interventions that suggested harm.
Of 1567 eligible interventions, 87 (5.6%) had high-quality evidence on first-listed primary outcomes, positive, statistically significant results, and were rated by review authors as beneficial. Harms were measured for 577 (36.8%) interventions, 127 of which (8.1%) had statistically significant evidence of harm. Our dependence on the reliability of Cochrane author assessments (including their GRADE assessments) was a potential limitation of our study. 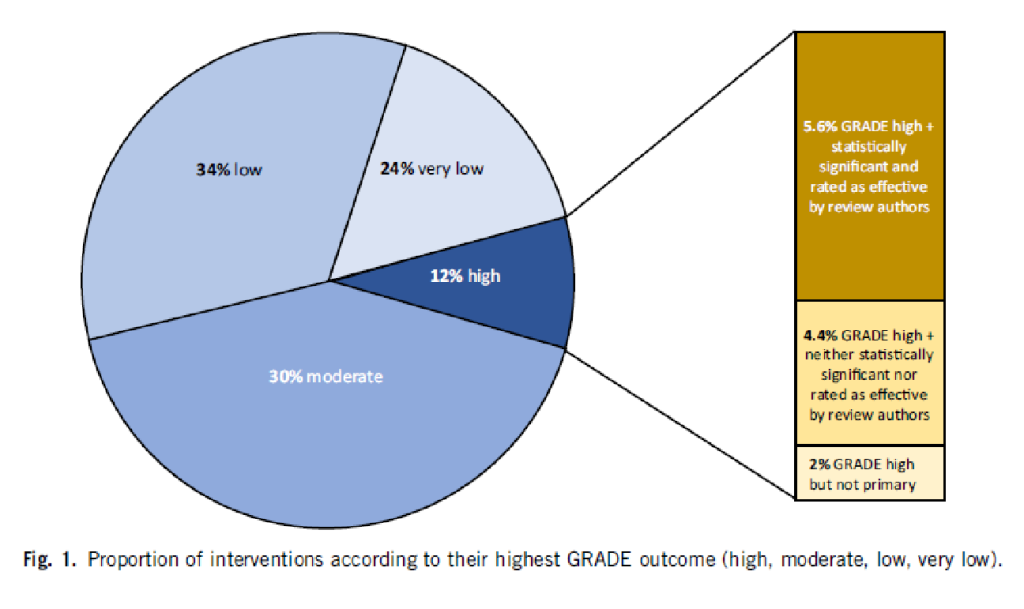
The authors drew the following conclusions: While many healthcare interventions may be beneficial, very few have high-quality evidence to support their effectiveness and safety. This problem can be remedied by high-quality studies in priority areas. These studies should measure harms more frequently and more rigorously. Practitioners and the public should be aware that many frequently used interventions are not supported by high-quality evidence.
Proponents of so-called alternative medicine (SCAM) are fond of the ‘strawman’ fallacy; meaning they like to present a picture of conventional medicine that is overtly negative in order for SCAM to appear more convincing (Prince Charles, for instance, uses this trick every single time he speaks about SCAM). Therefore I am amazed that this paper has not been exploited in that way by them. I was expecting headlines such as
Evidence-based medicine is not supported by evidence
or
Less than 6% of all conventional treatments are supported by sound evidence.
etc.
Why did they not have a field day with this new paper then?
As the article is behind a paywall, it took me a while to get the full paper (thanks Paul). Now that I have read it, I think I understand the reason.
In the article, the authors provide figures for specific types of treatments. Let me show you some of the percentages of interventions that met the primary outcome (high quality, statistically significant effect, and authors interpret as effective):
- pharmacological 73.8%
- surgical 4.6%
- exercise 5.8%
- diet 1.2%
- alternative 0.0%
- manual therapies 0.0%
So, maybe the headlines should not be any of the above but:
No good evidence to support SCAM?
or
SCAM is destroying the evidence base of medicine.
Evidently, everything is hypothesis-driven (otherwise complete randomness will take forever and get nowhere), hence there is “bias” from the start, as a necessity.
Hence, by definition, most context *must* be removed – hence at the limit, without any context, you can prove anything, no matter how preposterous – put back a little context, not too much and you can “prove” in one trial that X == true and also, in another trial that X == false.
E.g. The China Study where some critic will “prove” that it was “done wrong” (according to their criteria) e.g. the China Study “proved” that reduced animal protein reduced the risk of cancer whereas an enormous US study “proved” that reduced animal protein made no difference to cancer risk.
The difference in the trials was the starting hypothesis of what “reduced” meant wrt animal protein. In China during the 1980s it could mean almost down to zero, during the same time in the US it could mean below 20%, hence one trial “proves” one result, the other trial, the opposite.
could you please try to make some sense for a change?
The study which involves our “special friend” Harald Walach has been presented on Joseph Kuhn’s blog “Gesundheits-Check” (in German only).
https://scienceblogs.de/gesundheits-check/2022/06/19/john-ioannidis-und-harald-walach-wenn-zusammenwaechst-was-nicht-zusammengehoert/
And Harald Walach has already exploited the study on his blog: “Meta-Review: The backbone of evidence-based medicine is weak”
https://harald-walach.de/2022/06/17/meta-review-das-rueckgrat-der-evidence-based-medicine-ist-schwach/
very interesting!!!
thanks
Perfect. So, Edzie…you can dish out critique but can’t accept it when it is your team that is getting evaluated. The bottom line is that only a very small percentage of medical treatments have had a level of efficacy as determined by high-quality science. Way back in the 1970s, the US Office of Technology Assessment determined that only around 10% of medical treatment have been proven efficasious in controlled clinical trials. Now, modern medicine has progressed (backwards!) to only 6%.
And rather than acknowledge this serious problem and rather than express concern about the TRILLIONS of dollars spent on medical care every year, you do what good Big Pharma shills do by complaining about the little guys…and you have the real chutzpah for blaming the homeopaths to bringing down the average efficacy that is witnessed today.
You should win an Academy Award for feigning indignance. Congrats, you win this prize!
“your team that is getting evaluated”
what do you think is MY TEAM?
PS
thanks for coming up with another silly name for me
You do realize you’ve just admitted you don’t understand the significance of this study’s findings or the whole basis of empirical science, don’t you?
Oh silly me, of course you don’t.
Oh dear Dana.
Medicine looks at itself and does its best to correct itself. AltMed types do not. Particularly homeopaths. You have NEVER changed what you do as a result of evidence. If you did, you would’ve given up on magic shaken water years ago. But you can’t because you’re a blinkered zealot incapable of rational evaluation of anything which is why you remain the inconsequential, jabbering, flailing and posturing figure of ridicule that you are. Run along now, Rumpelstiltskin.
The 400+ studies in peer-review journals favor homeopathic treatment. Actually, it is the people HERE who cherry-pick their evidence because the bulk of randomized double-blind trials. Evidence of relevant benefits is simply the number of oncologists who have incorporated homeopathy into their practice and who refer for homeopathic treatment.
Here’s some strong evidence for this:
Homeopathy is the most frequently used complementary therapy in supportive care in oncology (SCO) in France today, and its use in cancer treatment is steadily increasing. Two cross-sectional surveys of French physicians were conducted involving (1) 150 specialist oncologists; (2) 97 homeopathic MD general practitioners (HGPs) and 100 non-homeopathic MD general practitioners (NHGPs) (Bagot, Theunissen, Serral, 2021).
This survey found that 10% of oncologists stated they prescribe homeopathic medicine for patients with cancer; 36% recommend homeopathic medicines for general health concerns; 54% think that homeopathic medicines are potentially helpful in cancer treatment. Two-thirds of the NHGPs sometimes prescribe homeopathy in the context of cancer treatment, and 58% regularly refer their patients to homeopathic doctors.
The researchers concluded that homeopathy is viewed favorably as an integrated SCO therapy by the majority of French physicians involved with cancer patients-oncologists and GPs. Symptoms of particular relevance include fatigue, anxiety, peripheral neuropathy, sleep disturbance, and hot flashes. In such clinical situations, response to conventional therapies may be suboptimal, and homeopathy is considered a reliable therapeutic option. These surveys highlight the fact that homeopathy has gained legitimacy as the first complementary therapy in SCO in France.
Bagot JL, Theunissen I, Serral A. Perceptions of homeopathy in supportive cancer care among oncologists and general practitioners in France. Support Care Cancer. 2021 Mar 24. doi: 10.1007/s00520-021-06137-5. Epub ahead of print. PMID: 33763723. https://pubmed.ncbi.nlm.nih.gov/33763723/
“The 400+ studies in peer-review journals favor homeopathic treatment.”
we discussed this often before. the thing is, you need to take into account the quality of the studies. if you do this, the conclusion is that the body of the reliable evidence fails to be in favor of homeopathy.
Oh Dana
A Boiron customer satisfaction survey? And where do you imagine this sits on the hierarchy of evidence? That you are capable of deluding youself that this barrel-scraping twaddle supports your position says much. The horse is dead, Dana. It’s not going to move no matter how hard you kick it.
Dana Ullman quoted from the same source in his comment on Wednesday 31 March 2021 at 14:32, to which Edzard and Lenny replied:
https://edzardernst.com/2021/03/a-truly-perplexing-homeopath-is-it-time-for-an-official-investigation/#comment-131004
I’d forgotten that!
At least I’m consistent in my replies!
Well-designed homeopathy studies produce random results, as one would expect when the intervention being tested has zero effect.
Correct me if I’m wrong, but wouldn’t one expect a slightly positive result when aggregating studies for an intervention that has no real effect (e.g. homeopathy)?
When looking at individual studies, there are three possible results:
1: the treatment group does significantly better than the control group.
2: there is no significant difference between the treatment group and the control group.
3: the treatment group does significantly worse than the control group.
The point is that #2 and #3 are both counted as ‘zero effect’. When aggregating study outcomes, this inevitably leads to an overall outcome of ‘some effect’; the (numerically) negative outcomes in #3 can’t compensate for positive outcomes in #1, even if they both arise from the same statistical noise.
If the study is well designed with an informative control (where all factors are equivalent between intervention and control groups or otherwise accounted for) and the intervention itself has no effect, then “results” will tend to be random. Some people will get better, some will get worse, and some will experience no change, and this data will be the same in the intervention and control groups.
@Christine Sutherland
I think I understand what you mean, but because I think this is quite important, I want to go over this once more. So we have a study where the intervention under scrutiny has no effect, assuming that the study is well-designed etcetera.
Yes, for individual participants both in the treatment group and the control group, the outcome (effect or no effect) is random. However, the study as a whole will not have a random outcome – it will most likely have a negative outcome (as in: no effect, so the null hypothesis is not rejected), but still with a small chance that it has a positive outcome.
And thus when looking at a lot of studies of the same ineffective treatment, we will see mostly negative (‘no effect found’) outcomes, bit still a few false positive ones (‘effect found’) as well. It is these last ones that will always cause an overall positive score, even if it is usually very small – because numerically negative outcomes (i.e. worse than ‘no effect’) are not recognized as such. Basically, studies produce a binary result of either rejecting the null hypothesis or not rejecting it, without assigning a sign or a weight(*).
This is what I mean when I say that when looking at multiple studies, even a treatment that has no effect over placebo will still produce a small positive result due to statistical noise.
And it is this minute false positive result overall that is often interpreted by proponents of alternative treatments as evidence that there must be ‘something’ to whatever they are pushing.
*: I think this sign/weighing problem is similar to the problem of trying to account for prior plausibility (Bayesian statistics). Then again, I am not a scientist, and I never conducted or even analysed a study in accordance with proper scientific standards, so chances are that I’m misinterpreting something.
Richard when there is no difference between outcomes in the treatment and control group, where some people experience improvement, some get worse, and some get better (in the same ratios) then there is zero evidence that the intervention is of benefit and claims of positive outcomes are unreasonable and unsupported. There is simply no other way to twist that.
I’m not sure if we’re on the same page.
Christine
You are notionally correct in what you say but, as Richard says, John Ioannidis and others demonstrated that inert therapies will demonstrate a small positive response – it’s to do with Bayesian stuff and the complexities of prior plausibility. It’s why the idea of science-based rather than evidence-based medicine came about.
From the Wiki on homeopathy:
@Christine
That’s what I also think, hence my attempt to explain what I mean.
Yes, I completely agree with your line of reasoning: if a particular treatment doesn’t have any effect compared to placebo, then indeed some study participants will by pure chance fare a little better, others will be doing somewhat worse. And if we add up observed outcomes of the treatment group (positive AND negative(*)), and then do the same for the control group, and finally subtract the two aggregated scores, we should expect a net zero outcome. So far, so good.
However, this is where statistical noise may throw sand in the machinery: purely by chance, the treatment group in a particular study may show a better outcome than the control group, i.e. a false positive effect of the treatment. Of course the opposite can also happen, so the treatment group doing seemingly worse than the control group(**).
Now what I’m aiming at is that studies showing a (false) positive effect are indeed counted as such. But if these same studies have a negative (less than zero) effect, so the treatment does more harm than good, then the result is considered zero, as in ‘no effect’. The fact that the actual outcome is worse than zero is not reflected in this result.
This is what I mean by a binary outcome: either we have a positive outcome and thus are able to reject the null hypothesis, or we do not have a positive outcome, so we retain the null hypothesis for the time being.
And this is where I think a problem arises: when reviewing a large number of studies, there will be some with a false positive outcome, and those are counted as showing an effect. The ones with a mathematically negative outcome (so the treatment group is doing worse) are NOT counted in a negative sense; instead they are lumped in with the ‘no effect’ set.
As a result, you end up with a lot of studies showing no effect, but always a few that appear to show an effect that isn’t really there. Proponents of alternative modalities will latch onto the latter group, claiming that the effect may be small, but that it is there nevertheless, and should be taken seriously, investigated further etcetera.
I think the best solution would be to retain the numerical effect size (and of course whether it is positive or negative) in the outcome of a study, and use that rather more informative value instead of just looking at rejecting or keeping the null hypothesis.
I hope my argument is clearer now 🙂 And please correct me if there are flaws in my reasoning (e.g. when reviews already take effect sizes into account).
*: One confusing thing here is the double meaning of the word ‘negative’: in studies, a negative outcome is a zero outcome, so no effect. However, in calculations, negative means ‘less than zero’, e.g. if a treatment does more harm than good, it has a negative effect.
**: False outcomes due to statistical noise or outliers of course become more likely with smaller samples. And I think that studies of alternative treatments more often than not have relatively small sample sizes, increasing the chances of a false positive result.
Thanks Richard, I understand, and feel we’re pretty much in step agreement.
Researchers do seem to cling to statistical noise, claiming significance for outcomes that aren’t in any way clinically significant.
Just one of many things that are wrong with current psych studies for example.
I wrote the following previously[1], but it’s worth stating again…
If a clinical trail compares A vs B, it is extremely unlikely that zero difference can be detected when A and B are identical; such as homeopathic water vs other water.
The same is true when attempting to measure the bias in a random number generator or a coin. The probability P of obtaining zero bias in a truly unbiased coin reduces as the number of coin tosses (trials) N increases:
N=100 P=8% chance of result=0 bias
N=1000 P=2.5%
N=10,000 P=0.8%
N=1 million P=0.08%
etc.
In parapsychology, increasing values of N are used to give the impression that the ‘tests’ have increasing power to detect the phenomenon under investigation. Whereas all that’s happening by increasing N is reducing the chance of getting a zero result; an absence of the phenomenon under investigation. Not very clever, yet clever enough to fool those having a desire to believe in the paranormal.
RCTs are for estimating the size of an effect (science); not for detecting whether or not the effect actually exists, which is pseudoscience, especially when the A and B being tested are identical.
1. https://edzardernst.com/2022/03/the-body-of-evidence-on-homeopathy-is-rotten-to-the-core/#comment-138296
Dana, did you actually read the blog post you were replying to here?
Of course he did. The blog post says what Dana imagines it says. That’s how words and reading and comprehension work in his world.
EE: No good evidence to support SCAM?
A more proper conclusion would be:
There is no high quality evidence to support the CAMs that were included in the study.
And when using GRADE there are several reasons for down grading an approach.
https://bestpractice.bmj.com/info/us/toolkit/learn-ebm/what-is-grade/
Could anyone with more medical knowledge comment on the seemingly poor result for surgical intervention? The drug response looks very good but the surgery result surprised me.
What’s going on? Unrealistic expectations from surgery? Is is mostly used in cases with a poor prognosis? Some anomaly in the survey?
Scam results not so good – surprise!
I think the poor results of surgery are due to
1) relative paucity of trials
2) methodological difficulty doing these studies
Of course, I should have realised. A placebo surgical intervention would difficult and almost certainly unethical.
Placebo controlled studies of surgical procedures have been done but these were rare exeptions.
The reported paucity of ‘high quality evidence’ for surgical interventions is to be expected and normal. As has been said here, it is simply a matter of definition. Also, when you say “surgical” the word means extremely many, varied and wildly different things, anything from addressing an ingrown toenail to double lung and heart transplants and beyond. I dare say that ‘high quality’ research is being done all the time within surgery, it just means something other than placebo controlled, blinded and randomised trials gold standard evidence,that seems to be the yardstick here.
Most good surgeons do audit and evaluate their practice continuously but such evaluations are by definition not gold standard controlled, blinded, randomised trials. What is important in respect to evidence for the utility of a surgical imtervention is prior probability and good aplied knowledge of physiology, pathology and anatomy. As an example, if you shorten the alimentary channel, the absorption of nutrients may be affected. Extremely complex factors decide what will happen if you remove or bypass a part of the gut and the collected experience of decades of such interventions have taught us to use shortening of the alimentary tract relatively safely to acheive weight loss in those suffering from obesity. (Bad) experience has historically taught us not to shorten certain parts of the gut and how much and in what way to do the procedures has evolved from both experience and research. Randomised, blinded studies are also used with caution to compare different versions of such procedures, e.g. different lengths of bypassed gut but placebo control is simply not an ethical approach to further our surgical knowledge, except in animal models of such interventions, which then are tried in ethically controlled tests in human volunteers.
Due to the nature of the criteria for the review:
“We extracted data about interventions within these reviews that were compared with placebo, or no treatment,””…”
Hence, limited studies will downgrade.
Preprint of the paper is here:
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4031358
Before having to take early retirement due to ill-health I was an oncologist mainly treating urological cancers (prostate, testicle and bladder with a few rare ones from time to time). I once attended a urological conference (I think it was the European Association of Urology) and I was quite shocked at what surgeons were happy to accept as evidence.
As an oncologist I am used to basing my practice on large, rigorous, multicentre (and often international) randomised trials, and I would regularly update my protocols as new data from these became available. However, it seemed that all it took for surgeons to adopt a new technique was a case series showing that it was feasible, and perhaps an outcome study which really amounted to an audit rather than a trial. In my experience surgeons are remarkably resistant to taking part in randomised trials, partly because they are convinced that they are already giving the best treatment, and partly because the idea of determining the management of an individual patient on a throw of a dice goes completely against their way of thinking.
I remember a few years ago there was a large UK trial (named SPARE) organised to investigate surgery versus radiotherapy for muscle-invasive bladder cancer. The received wisdom is that treatment should be surgery, with radiotherapy reserved for those too unfit or unwilling to undergo radical cystoprostatectomy, or cystectomy with hysterectomy. Those of us who have treated these patients with radiotherapy know that they often do very well, the treatment is well tolerated, and they still have a bladder at the end of it. A trial design was eventually agreed whereby subjects would initially be randomised between primary surgery and primary chemotherapy. At the end of the chemotherapy, if they had had a complete response to chemo then there was a second randomisation between surgery and radiotherapy; if the response was incomplete then they had surgery anyway. This design (with most people ending up with surgery) was the only way to get the surgeons on board. However, once the trial opened, virtually no patients were entered into it, and it folded within the first year. The individual urologists concerned each maintained that while, in principle, they were in favour of the study, they felt that surgery was the better option for the patient they had just diagnosed.
By its nature, surgery leaves little room for doubt. A physician can try a treatment and change his mind if the patient doesn’t respond as expected, but there is no going back from an operation, and the surgeon has to believe that what he is doing is the right thing or else he wouldn’t be able to do it. Unfortunately that mind set doesn’t favour clinical trials very well.
Surgeons, Julian? Thinking they know everything and can do everything? Surely not!
The best evidence of God’s good judgement is that she does not think she is a surgeon 😉
Here’s a thing which came past today – looking into surgical complications to orthographic surgery. Not a true comparison study, no placebos, etc, but working with a lot of data and producing some pretty solid conclusions. Prophylactic removal of third molars is no longer indicated. Hopefully surgery will change. https://www.nationalelfservice.net/dentistry/oral-and-maxillofacial-surgery/sagittal-split-osteotomy-third-molars-increase-risk-complications/
Why did Cochrane include SCAM studies, admitting that conventional, scientifically oriented medicine should be included in the acronym MEDICINE when it is excluded as an alternative? Of course, Cochrane carries out systematic reviews on SCAM, but it does so, I believe, as an act of social responsibility and enlightenment for the population that, to a significant extent, resorts to them. On the other hand, 73% of the evidence for established drug therapies is a very respectable result and these therapies are therefore corroborated in the Popperian sense. Professor Edzard Ernst is right to assume that clinical trials of complex surgeries do not lend themselves to controlled clinical trials due to almost insurmountable obstacles, including those of an ethical nature. Surgery has experienced extraordinary advances and its testability is being gradually processed with repetitions, comparisons and evaluations of all kinds.